Creating a TikTok Affiliate AI Expert with NotebookLM
The Problem with Learning Online Businesses from the Internet
There are a few inconvenient facts about learning online businesses from the internet. Many who share their knowledge like to hang out on YouTube, podcasts, and other short-form platforms not intended for deep knowledge transfer. Even in long-form formats—even blog posts titled “How To…”—it’s rare to find the comprehensive, step-by-step guidance needed to get from zero to sixty in one straight shot. That’s fair. Real-world knowledge transfer often happens in the haphazardness of human conversation and the trial-and-error of shared experience, not just in tightly-structured tutorials.
People usually have a few options when learning online businesses from the internet:
1. Consume hundreds of YouTube videos, podcast episodes, and blog posts. Get distracted by the algorithms. Eat lots of fluff in the quest for substance. Exhaust time and energy parsing information unrelated to the present point in the journey. Miss critical knowledge out of ignorance, bad advice, and biased omissions. Get overwhelmed before ever starting.
2. Buy a course and join a community. I’ve had mixed experiences with this one.
I bought a project management course on Udemy that was great. A lifetime educator taught the course, he’d incorporated feedback from tens of thousands of students into his course’s design, and it was his third or fourth iteration. It was solid.
I also bought an Amazon FBA course pitched by a YouTube bro that led to financial tragedy. Bro was succeeding. Bro had social proof that others were succeeding. Bro’s delivery was polished and easy to follow along. Bro covered all the mechanics I needed to get started. Bro was also financially incentivized to not disclose that his strategy was like walking through a minefield. I didn’t know what I didn’t know until something went boom—in my case, Amazon competing against its third-party sellers by bringing common products to market faster and at a lower price-point than I could get my own inventory into their warehouses. Total wipeout.
3. Drop digits and hire a coach. Coaches are great once a business is off the ground and profitable. They usually aren’t meant for someone starting from zero.
The internet is full of people pitching online gimmicks they haven’t mastered themselves. A small set of them have actually mastered the thing they’re pitching. Even of those who are successful, few are skilled at transferring their knowledge for success to others. They’re the worthwhile guides to buy courses from and the ones to hire as coaches.
If you’re starting from zero, don’t know what you don’t know, and just want a super-detailed map from the start of your journey, where do you turn? Courses for beginners aren’t meant to cover comprehensive detail. Coaching is probably out of reach. There’s vast amounts of free information to glean from. It’s just not practical to wade through all of it to get the answers you need.
Enter NotebookLM.
NotebookLM: The Solution to Digesting Freely Available, Unstructured Information into a Giant Knowledge Repository
I was inspired to build a custom knowledge base from listening to the podcast The Art of Selling Online Courses. John kept mentioning Josep AI, an AI-coach trained from Josep’s own content. I looked up Coachvox, the platform it’s built with. Using Coachvox would have been like using Salesforce in a hair salon. It was more tooling than I needed, cost more than I wanted, and didn’t even fit my needs.
After a bit of Google, Reddit, and Perplexity searching, I came across Google’s NotebookLM. It fit my use case perfectly. It has a minimal interface; a generous free tier; is intended for single-person use; has processing capacity far beyond OpenAI and Anthropic’s models; and, most importantly, generates answers exclusively from uploaded materials.
If details like AI model design and token context windows excite you, this comparison from Perplexity is what sold me on using NotebookLM:
Explain how NotebookLM's model context window compares to other RAG-capable AI tools.
NotebookLM’s context window in 2025 far surpasses most RAG-capable AI tools, both in size and in how it integrates retrieved content from user-uploaded sources. It allows users to process a vast library of files in one workspace while maintaining strict source grounding.
Context Window Scale
NotebookLM, powered by Google’s Gemini 2.0 Flash model, supports up to 2 million tokens per project, equivalent to about 1.5 million words or 3,000 pages of text. As of mid‑2025, the system supports up to 300 sources in a single notebook, accommodating around 150 million words through advanced compression and contextual routing. This allows it to map and relate content across multiple books, PDFs, or transcripts without losing coherence.
By comparison:
| Platform | Token Limit (approx.) | Words | Equivalent Pages | Context Type | Sources |
|---|---|---|---|---|---|
| ChatGPT (Free) | 4K–16K | 3K–12K | 6–24 | Inline | Single file |
| ChatGPT Plus (128k) | 128K | 96K | 192 | Inline | Single PDF/report |
| ChatGPT Enterprise / o1-preview | 200–400K | 150K–300K | 300–600 | Inline RAG | Multi‑file, slower |
| Claude 3.5 Sonnet | 200K–400K | 150K–300K | 300–600 | Inline | Multi‑file |
| NotebookLM (Gemini 2.0 Flash) | 2 M | 1.5 M | 3,000 | RAG‑enhanced + long context | 300 sources |
Relationship to RAG
Unlike conventional RAG systems, NotebookLM’s architecture merges retrieval and long-context reasoning. When you query it:
- It retrieves small relevant fragments (as in RAG),
- Then extends its reasoning within a massive 2 million-token context window, letting it truly connect ideas across entire documents rather than sampling isolated snippets.
- Because it grounds every answer exclusively in those uploaded sources and displays citations inline, it minimizes hallucination while functioning like an integrated library assistant.
Summary
In essence, while tools like ChatGPT or Claude combine RAG with context windows under half a million tokens, NotebookLM operates at a magnitude larger—millions of tokens and hundreds of documents at once, effectively transforming Google’s product into a hybrid between a research database and a long-memory LLM. This makes it uniquely capable of synthesizing insights across vast multi-source repositories while remaining strictly source-grounded.
Maxing out NotebookLM’s Capacity by Scraping YouTube Videos and Merging Sources
NotebookLM has pretty generous free-tier limits. A free notebook can hold up to 50 sources, each the lesser of 500,000 words or 200MB. The immediately constraining limit for me wasn’t going to be word count or file size, but source count. Upgrading to the paid version (which increases the source limit to 300) wouldn’t help much. I wanted to pull over 1000 YouTube videos, all of TikTok’s policies related to its affiliate program, as well as a few related blog posts.
Here’s the thing: people don’t care if an anthology packs 100 stories into a single volume, and LLMs don’t care how much text gets packed into a single document. The more relevant information they’re given, the better their answers. The free tier of NotebookLM has ample capacity for my use (25M words). If I’d used the super-convenient “add from link” button, I would have maxed out my notebook’s limits long before adding a single YouTube channel. Instead, I needed to pack my sources into composite documents before uploading them.
Like all good internet-business wannabees, I began my search for TikTok affiliate “experts” on YouTube. I started with a routine video search. If the host talked about their success, I opened their channel in a new tab. If the video was a deep-dive interview, I opened the channel in a new tab. If the video was titled “How To…” but didn’t demonstrate success, skip. If it was a faceless video, skip. If it was a commentary on someone else’s success, skip. Then I worked through my open tabs of channels. Did the channel’s description say it was about TikTok affiliate? Gold star. Did the channel contain videos about every internet opportunity imaginable? Skip. Was the channel somewhere in-between? I’d skim more videos, decide if they were worth scraping, and then search for “TikTok” inside those mixed-focus channels to get a filtered list of videos.
Next up was scraping the 1000+ videos I’d found. There would be no benefit in feeding NotebookLM the video or audio streams straight from YouTube. I wanted to stay under the 200MB file size limit and maximize my constraints at 500,000 words per source. All I needed from the videos were their transcriptions. I could have parsed them into polished transcripts using any number of text-to-speech AIs, but YouTube’s automatic subtitles, though messy, were good enough for feeding into an LLM.
I needed a scraper that could batch extract YouTube’s automatic subtitles. yt-dlp did the trick. After a bit of Docker setup, python installation, $PATH debugging, SSH tunneling and cookie extraction for YouTube bot-dodgery, command-line fidgetry, and a bit more help from Claude, I had a YouTube scraper running on my server just gobbling up subtitles. Even so, it still took a few hours to ingest the YouTube channels I’d picked, catch the occasional scraping error, and re-sync my cookies every so often to keep up with YouTube’s bot-dodgery.
#!/usr/bin/env bash
# Install yt-dlp inside a debian:stable-slim container
apt update
apt install curl python3 python3-pip xz-utils -y
curl -L https://github.com/yt-dlp/yt-dlp/releases/latest/download/yt-dlp -o /usr/local/bin/yt-dlp
chmod a+rx /usr/local/bin/yt-dlp
curl -L https://github.com/yt-dlp/FFmpeg-Builds/releases/download/latest/ffmpeg-master-latest-linux64-gpl.tar.xz -o /root/ffmpeg-master-latest-linux64-gpl.tar.xz
tar -xf /root/ffmpeg-master-latest-linux64-gpl.tar.xz
rm /root/ffmpeg-master-latest-linux64-gpl.tar.xz
export PATH="$PATH:/root/ffmpeg-master-latest-linux64-gpl/bin"
echo 'PATH="$PATH:/root/ffmpeg-master-latest-linux64-gpl/bin"' >> ~/.bashrc
pip install "yt-dlp[default,curl-cffi]" --break-system-packages# yt-dlp configuration to scrape auto-subs for all videos in a channel,
# bypass YouTube's bot protection using browser-exported cookies,
# and remember download progress after stopping for errors
$ yt-dlp --abort-on-error --force-write-archive \
--skip-download --sub-lang en --write-auto-sub \
--cookies "/root/files/cookies.txt" \
--download-archive "/root/files/download-archive.txt" \
--extractor-args "youtube:player_skip=webpage" \
--match-filters '!is_live & live_status!=is_upcoming & availability=public' \
--output "%(channel)s/%(title)s.%(ext)s" \
https://www.youtube.com/@CHANNEL/videosAfter I scraped the subtitles, it was time to check their formatting. The .vtt subtitles were a mess to read through. AI probably would have understood them even with timestamp metadata and duplicate text, but I wanted my sources to read like (bad) English from inside NotebookLM. With some more help from Claude, I managed to strip them down to bare-bones, human-readable .txt files.
#!/usr/bin/env bash
# Convert VTT files to readable txt files
for file in /root/files/*/*.vtt; do
txtfile="${file%.vtt}.txt"
[[ -f "$txtfile" ]] && continue
tmpfile="${file%.vtt}.tmp"
sed -E -e '1,3d' -e '/^[[:space:]]*$/d' -e '/[0-9]{2}:[0-9]{2}:[0-9]{2}\.[0-9]{3}/d' -e '/.*<\/c>/d' "$file" > "$tmpfile"
sed 'n;d' "$tmpfile" > "$txtfile"
rm "$tmpfile"
done The last step was to consolidate the transcripts into a single document per channel to stay under NotebookLM’s source limit. I wrote a script with Claude to consolidate the transcripts. NotebookLM said there was an error uploading one document, but it didn’t say why. I found the culprit using my text editor’s word count: 4.8M words for that channel. Claude helped split its contents across four documents, and I uploaded them to NotebookLM.
#!/usr/bin/env bash
# Consolidate all .txt files by channel
cd /root/files/
for dir in */; do
dirname="${dir%/}"
master="${dirname}.master"
if [[ -f "$master" ]]; then
continue
fi
> "$master"
for file in "$dir"*.txt; do
[[ -e "$file" ]] || continue
echo "[$(basename "$file")]" >> "$master"
tr '\n' ' ' < "$file" >> "$master"
echo -e "\n" >> "$master"
done
doneMission accomplished. 1268 YouTube videos imported to NotebookLM, with plenty of source count to spare.
Balancing YouTuber Optimism with TikTok’s Official Policies
YouTube is a great place to find tricks and techniques. For instance, some YouTube channels love showing how to create AI-generated influencers. Those tutorials rack up view count on YouTube. They’re also terrible advice. Mishandled AI is a fast-track to getting banned from TikTok’s affiliate program for producing deceptive and misleading content.
Compliance is important when considering business strategy. YouTube isn’t the place to find compliance advice, though. TikTok’s website is.
I searched Google for policies relevant to TikTok’s affiliate program. I also tried using Perplexity to fill out the list. Unfortunately, I had to comb through TikTok’s Policy Center and Feature Guide for affiliates and for sellers, as well as their global legal website, to find the sources I wanted to pull.
There was no automated document scraping this time. Perplexity didn’t always know the difference between policies applicable to affiliates and policies applicable to sellers, and especially not which seller policies also impacted affiliates. TikTok’s HTML markup was also inconsistent. Unlike the YouTube subtitles, which I didn’t bother to format since the transcriptions were sloppy to begin with, I wanted to keep the TikTok policy scrape well-formatted so I could easily reference it inside NotebookLM. I converted each webpage into markdown. Then I cleaned up each file using my text editor. Once I’d polished off everything, I merged them all into a single document and uploaded it to NotebookLM.
TikTok policies relevant to affiliates: 99,198 words. One document.
Mission accomplished. Plenty of source count left to spare.
Red Herring Cleanup and a Bit of Finessing
Without prompting, NotebookLM knew the topic was TikTok affiliate marketing. It generated a diverse and well-structured overview of topics. It also gave a nod to setting up affiliate programs using WordPress, Shopify, and Facebook ads.
Where were those coming from? Remember the 4.8M word transcript I split earlier? Well, NotebookLM kept citing that channel when I asked about WordPress and Shopify. I double checked the YouTube channel. Of 279 videos, six were about TikTok. Two were about the TikTok affiliate program. Oops.
Garbage in. Garbage out.
Time to throw out my largest source documents.
The more I asked NotebookLM questions and read through answer citations, the more I saw who had broad expertise and who remained at surface level. I’d decided to include one channel despite thinking the host was a hack, but he turned out to be one of the better sources of expertise.
I started renaming my sources inside NotebookLM to mark their corresponding reference frequency. Four sources didn’t even get referenced. Maybe they were fluff, but I left them in in case they might hit a niche topic later on. I axed another two that were contaminating my notebook with eau de douchebaggery.
The last thing I fiddled with was NotebookLM’s conversation style. Default was chatty. Learning Guide would ask me questions instead of answering my own questions. I asked Gemini for help writing a conversation style, but its suggestion was a convoluted mess. Eventually I settled on my own custom style and set the answer length to long.
Roleplay as a TikTok Affiliate Marketing Coach. Deliver to-the-point, thorough, and linearly structured answers, frameworks, and methodologies that showcase the nuances and complexities of the platform. Weave individual anecdotes into answers. Use a dynamic output format adjusted for query complexity. Do not provide conversational introductions, fillers, or follow-up questions.
The Result
NotebookLM thoroughly impressed me.
Drawing from a giant, incoherent set of source materials, it built a crystal-clear, top-level breakdown more detailed than anything I could have put together after watching countless YouTube videos:
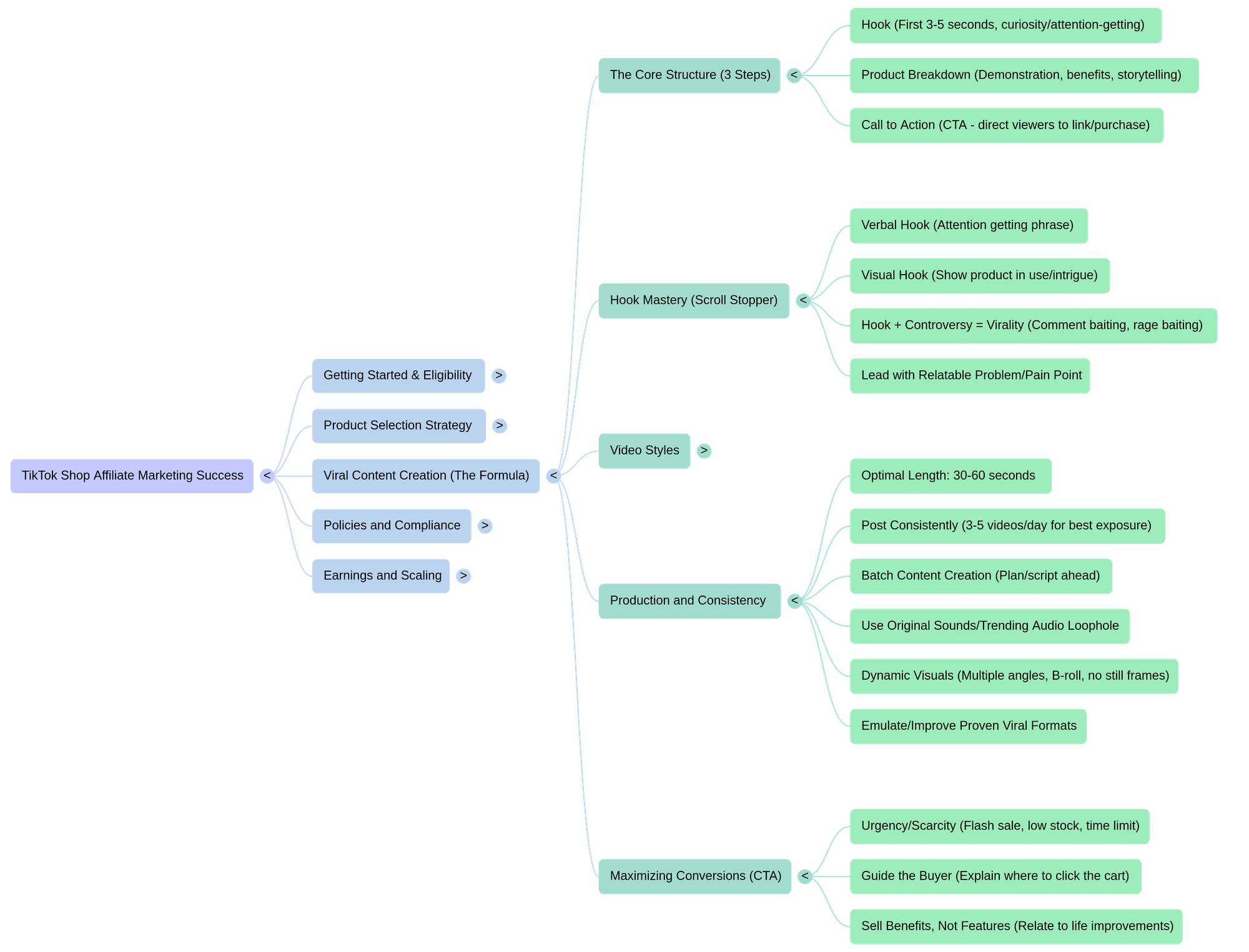
When I asked NotebookLM how to handle AI-generated content, it reshaped TikTok’s policies into a response more coherent and better structured than their own policies. NotebookLM started with generally-applicable policy (I), moved to specific distinctions between non-monetized (II) and monetized policy (III), and then seamlessly blended real-world examples from the videos I’d scraped to create a fourth section called Mixed AI & Real Media Content Strategies. What’s most impressive to me about that section is that NotebookLM knew exactly where to draw the line between acceptable practices, common but grey-area practices, and straight-up bad YouTube advice (which it entirely excluded):
TikTok AI Content Policy and Compliance
The nuances of artificial intelligence generated content (AIGC) on TikTok vary dramatically depending on whether the content is intended solely for entertainment or for direct commerce monetization. TikTok aims for authenticity and compliance, which tightens the leash significantly in the affiliate and shopping sphere.
I. TikTok's General Stance on AIGC and Disclosure
TikTok welcomes creativity, including content generated by AI, but requires transparency to ensure viewer trust and prevent misinformation.
Core Policy: Creators must clearly label content when generative AI or significant editing is used to realistically depict people or scenes. If AIGC is unlabeled, TikTok reserves the right to remove it, restrict its visibility, or apply a label automatically.
AIGC Prohibitions: Regardless of labeling, content is explicitly prohibited if it:
-
Misleads or deceives viewers.
-
Misleads about matters of public importance, such as a crisis event or political figures taking stances they haven't addressed.
-
Harms individuals, including using the likeness of private figures without consent.
-
Violates any existing Community Guidelines (e.g., hate speech, sexualized poses, or violence).
II. AIGC for Non-Monetization Purposes (General Content/FYP)
When AIGC is posted without direct product links or commercial intent, compliance centers heavily on proper disclosure:
Disclosure Required (Mandatory Labeling):
- If AI makes it look like a real person said something they didn't.
- If AI-generated audio mimics the voice of a real person.
- If a face is replaced with someone else's.
- If a background, object, or person is added or removed in a misleading way.
Disclosure Not Required (Allowed Without Label):
- Minor edits like color correction, reframing, or cropping.
- Using artistic styles, such as anime.
- Generic text-to-speech (TTS) narration, unless the voice is recognizable.
Creators should use the platform's AIGC label, or a clear caption, sticker, or watermark to ensure compliance.
III. AIGC for Monetization Purposes (TikTok Shop/Branded Content)
The content standards are significantly stricter when monetization is involved, as integrity directly impacts consumer purchasing decisions. TikTok prioritizes authentic content for selling environments.
Explicit Prohibitions & High Risk:
-
AIGC: Content created solely with AI is not allowed if it misleads, deceives, or impersonates. This includes AI voiceovers or pre-recorded audio in live streams.
-
Still Frame Content: Still images, screenshots, or slideshows that lack movement, original narration, or human presence are deemed low-quality content and may be restricted or flagged as irrelevant promotion. However, some affiliates use simple text-on-screen videos, and highly successful slideshows exist, though compliance dictates they must not cover more than 50% of the screen or lack real-time interaction.
-
Misleading Visuals: Using filters or digital effects that exaggerate product results (e.g., skin-smoothing, teeth-whitening, or artificially reshaping the body) is prohibited, even with a disclaimer.
Compliance Anecdote: I've seen firsthand how unforgiving the system is regarding authenticity and duplication. Reusing the exact same video footage, even if it's your original content, just to change the on-screen text or hook, resulted in a 24-point deduction and permanent suspension of affiliate privileges for one creator. This highlights the strict requirement for entirely unique video assets for monetization.
IV. Mixed AI/Real Media Content Strategies
The most successful current strategies often integrate AI for efficiency while keeping the human or authentic visual element paramount to satisfy compliance and conversion metrics.
1. AI-Assisted Scripting and Ideation: AI tools trained on GMV data, like viral script writers, are highly effective for generating high-converting hooks and scripts based on proven viral frameworks. This outsourcing of creative ideation significantly speeds up the process necessary for high-volume posting. This approach is generally compliant as long as the finalized content adheres to all marketing and claims restrictions.
2. AI Voiceovers + Original Footage: Using AI voices (like those generated by 11 Labs or specialized tools) combined with high-quality, original B-roll footage (shot on an iPhone) is a common faceless content model. While AI voiceovers are prohibited in livestreams, their status in recorded videos for non-official shop creators remains ambiguous but often used for scale and conversion.
3. AI Avatars as Hooks (High Risk, Emerging Trend): Some creators leverage advanced AI models (like VEO3) to generate compelling, highly entertaining, but potentially non-compliant video hooks (e.g., the Bigfoot content selling products). This content typically achieves massive views quickly. The strategy involves using the AI character as a highly engaging hook for the first 2-3 seconds, then immediately cutting to real, compliant footage of the physical product being demonstrated. The risk lies in using AIGC that misrepresents the actual product or fails to show the physical product clearly, which is a major policy violation.